无独显llama.cpp部署DeepSeek
ollama部署的生成速度较慢,这里使用llama.cpp替换它,生成速度快了许多。
下载llama
- 下载地址
- 这里下载
win-avx2,解压- 为了方便,为解压后的目录添加环境变量(不添加后续需要到解压目录执行
cmd命令)

量化模型
- 下载地址:https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/tree/main
- 推荐版本:
Q5/Q8量化版(平衡性能与显存占用)- 需梯子访问
加载和启用
- 将量化模型移动到
llama解压后的目录,为了方便,可以改个名字,如deepseek-r1-1.5b.ggufcmd执行下方命令-m是加载模型,xxxx.gguf是解压目录中的量化模型,在8080端口启动推荐使用
bat脚本+桌面快捷方式
bash
llama-server.exe -m deepseek-r1-1.5b.gguf --host 127.0.0.1 --port 8080UI界面
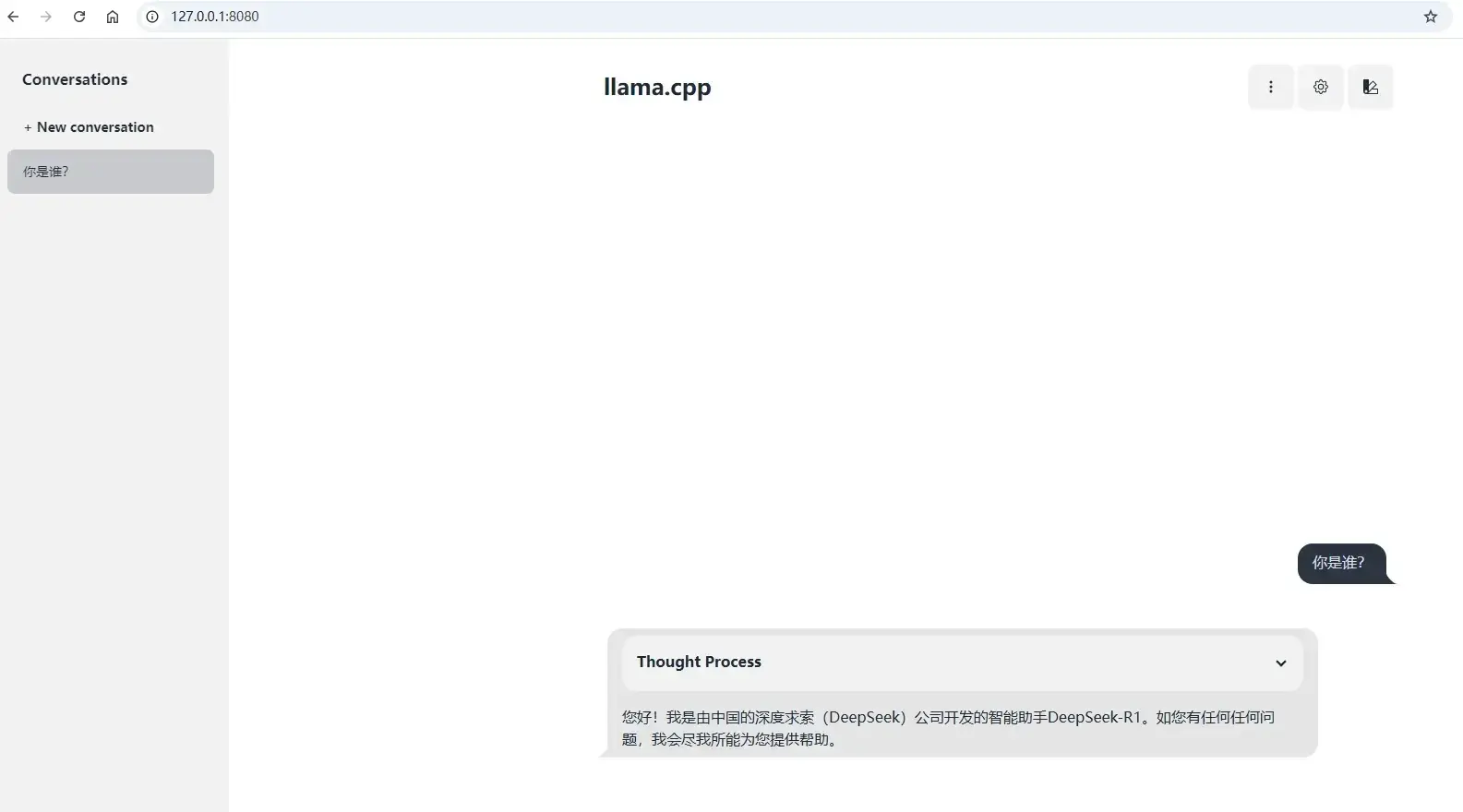
方式1:浏览器直接访问本机
8080端口
方式2:使用
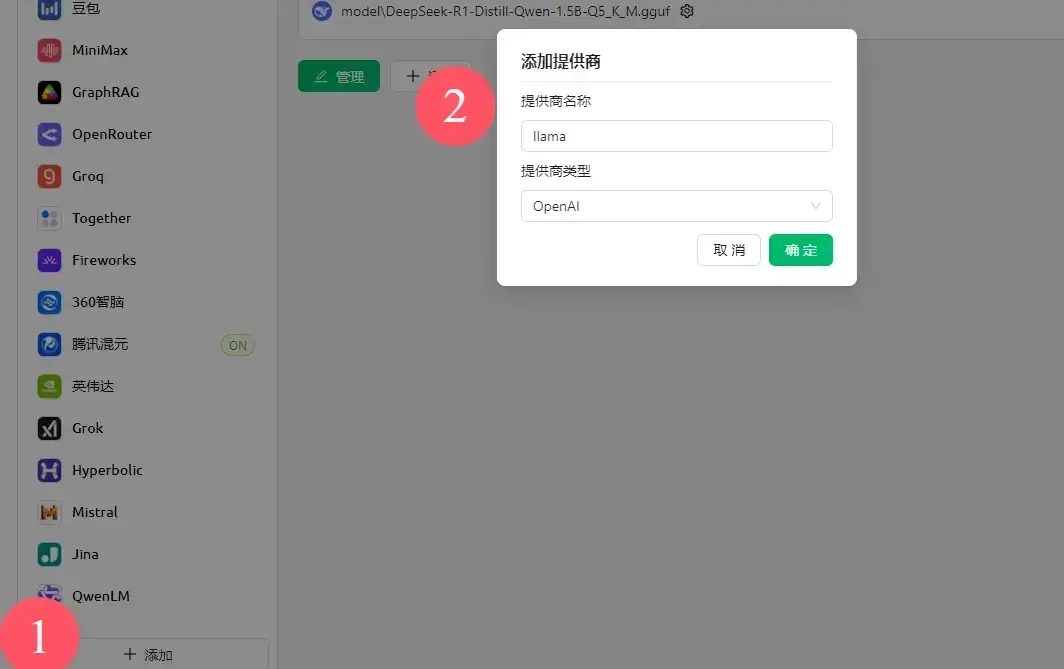
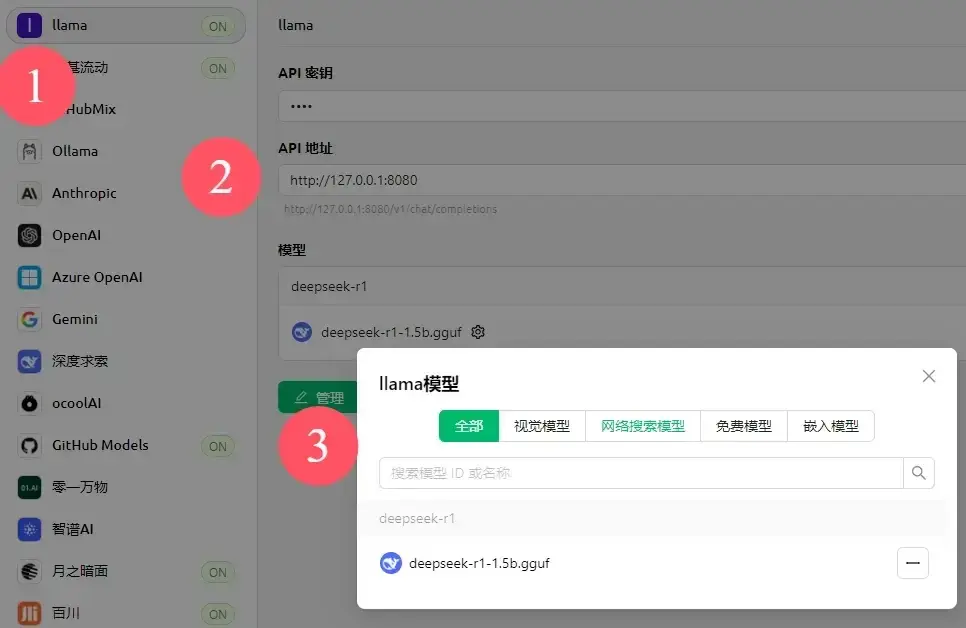
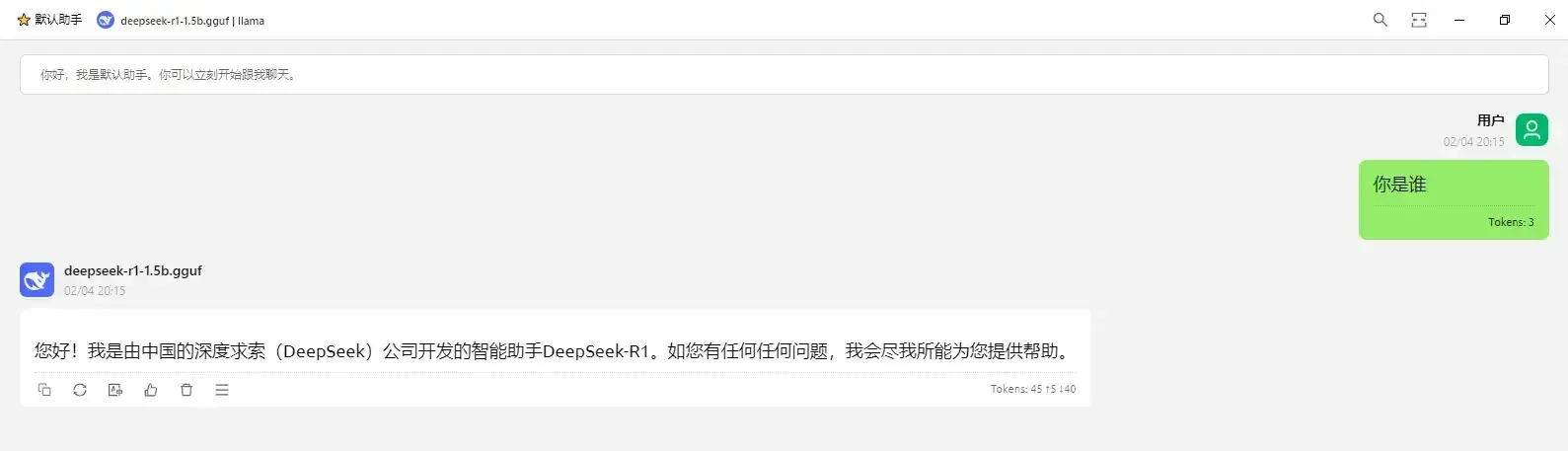
Cherry,之前我有介绍过(在无独显ollama部署DeepSeek)
- 创建服务商,随便填
- api key不需要或乱填,api地址填
http://127.0.0.1:8080,管理添加模型