AI摘要
参考0 成本实现 TianliGPT,实现纯本地的 AI 摘要 | 無名小栈,点击查看原文
下方内容仅供参考,注意我的
md原始文章都都是没有YAML front matter这一部分的
【改进】
完善了
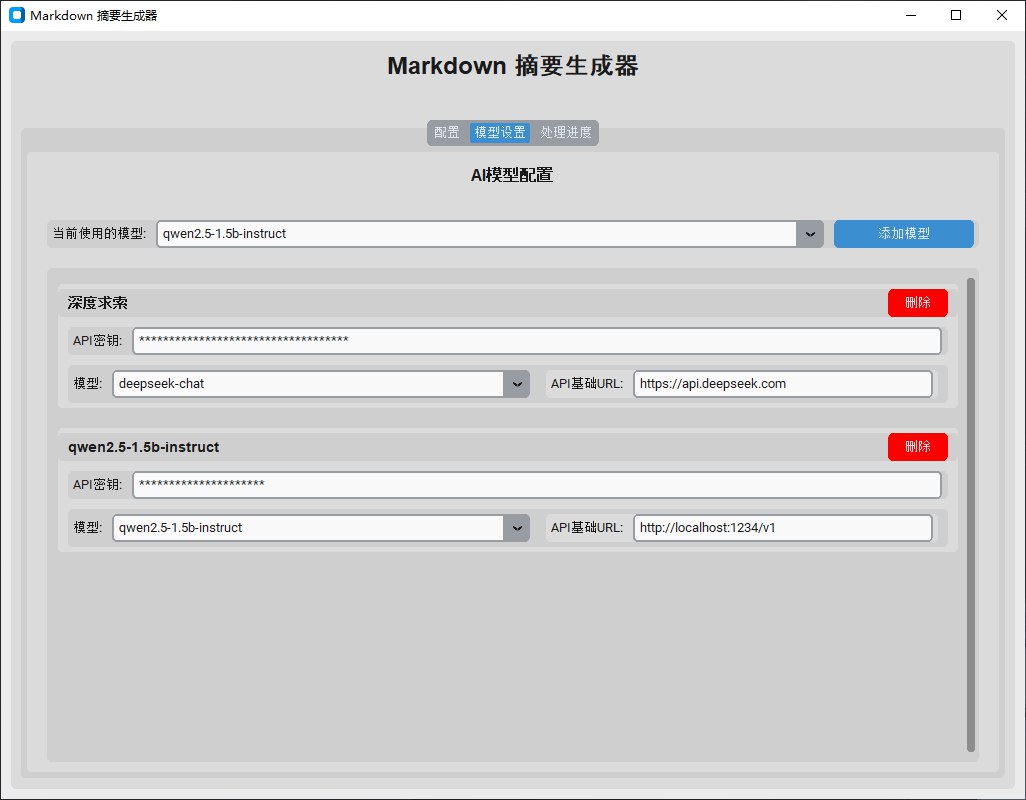
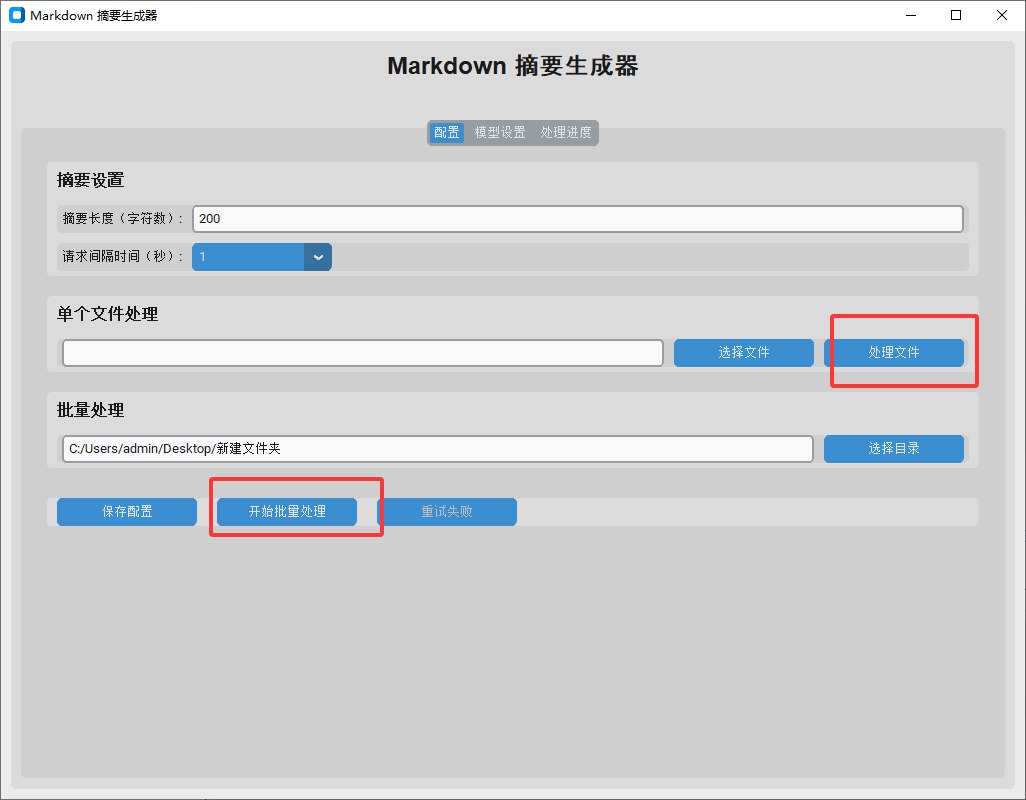
vitepress集成使用AI自动生成摘要,地址
摘要组件
docs\.vitepress\theme\components\ArticleGPT.vue
vue
<template>
<div v-if="frontmatter.articleGPT" class="article-summary">
<div class="summary-container">
<!-- 标题区域 -->
<div class="header">
<div class="title-section">
<div class="icon-wrapper">
<div class="icon">
<el-icon>
<ChatDotRound />
</el-icon>
</div>
</div>
<span class="title">文章摘要</span>
</div>
<div class="action-section">
<el-tooltip content="朗读文本" placement="top" :show-after="300">
<div class="speak-button" @click="toggleSpeak" :class="{ speaking: isSpeaking }">
<el-icon>
<Microphone />
</el-icon>
</div>
</el-tooltip>
</div>
</div>
<!-- 内容区域 -->
<div class="content-box" :class="{ 'loading-box': loading }">
<div class="bubble-container">
<p class="text" :class="{ 'is-typing': loading }">
{{ abstractData === "" ? "正在分析文章内容..." : abstractData }}
<span v-if="loading" class="cursor">|</span>
</p>
<div class="bubble-decoration"></div>
</div>
</div>
<!-- 底部信息 -->
<div class="footer">
<div class="meta-info">
<el-icon>
<InfoFilled />
</el-icon>
<span>此内容由AI生成,仅用于文章内容的解释与总结</span>
</div>
</div>
</div>
</div>
</template>
<script setup>
import { useData } from "vitepress";
import { ref, onMounted, onBeforeUnmount } from "vue";
import { ChatDotRound, Microphone, InfoFilled } from '@element-plus/icons-vue';
const { frontmatter } = useData();
const loading = ref(true);
const waitTimeOut = ref(null);
const abstractData = ref("");
// 语音相关状态
const isSpeaking = ref(false);
const speechSynth = window.speechSynthesis;
let utterance = null;
const typeWriter = (text = null, targetRef = abstractData, callback = null) => {
try {
const data = text || frontmatter.value.articleGPT;
if (!data) return false;
targetRef.value = ""; // 清空内容重新开始
let index = 0;
const type = () => {
if (index < data.length) {
targetRef.value += data.charAt(index++);
// 根据标点符号调整打字速度
const isPunctuation = [',', ',', '.', '。', '!', '!', '?', '?', ';', ';', ':', ':'].includes(data.charAt(index - 1));
const delay = isPunctuation ? Math.random() * (150 - 100) + 100 : Math.random() * (60 - 20) + 20;
setTimeout(type, delay);
} else {
if (callback) callback();
if (targetRef === abstractData) loading.value = false;
}
};
type();
} catch (error) {
loading.value = false;
targetRef.value = "生成失败";
console.error("生成失败:", error);
}
};
const toggleSpeak = () => {
if (isSpeaking.value) {
stopSpeak();
} else {
startSpeak();
}
};
const startSpeak = () => {
if (!abstractData.value || loading.value) return;
utterance = new SpeechSynthesisUtterance(abstractData.value);
utterance.lang = 'zh-CN';
utterance.rate = 1;
utterance.pitch = 1;
utterance.onend = () => {
isSpeaking.value = false;
};
isSpeaking.value = true;
speechSynth.speak(utterance);
};
const stopSpeak = () => {
speechSynth.cancel();
isSpeaking.value = false;
};
const initAbstract = () => {
// 创建一个更自然的加载延迟
waitTimeOut.value = setTimeout(
() => {
abstractData.value = "";
typeWriter();
},
Math.random() * (1200 - 800) + 800,
);
};
onMounted(() => {
if (frontmatter.value.articleGPT) initAbstract();
});
onBeforeUnmount(() => {
clearTimeout(waitTimeOut.value);
stopSpeak();
});
</script>
<style scoped>
.article-summary {
margin: 2rem 0;
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, 'Helvetica Neue', Arial, sans-serif;
}
.summary-container {
background: #ffffff;
border-radius: 12px;
padding: 0;
border: 1px solid rgba(235, 235, 235, 0.9);
box-shadow: 0 6px 18px rgba(0, 0, 0, 0.06);
overflow: hidden;
transition: all 0.3s ease;
position: relative;
}
.summary-container:hover {
box-shadow: 0 8px 24px rgba(0, 0, 0, 0.09);
transform: translateY(-2px);
}
.header {
display: flex;
justify-content: space-between;
align-items: center;
padding: 16px 20px;
border-bottom: 1px solid rgba(235, 235, 235, 0.8);
background: linear-gradient(to right, #f0f4f8, #edf2f7);
position: relative;
}
.header::after {
content: "";
position: absolute;
bottom: 0;
left: 0;
width: 100%;
height: 2px;
background: linear-gradient(to right, #3498db, #2980b9);
}
.title-section {
display: flex;
align-items: center;
gap: 12px;
}
.icon-wrapper {
position: relative;
}
.icon {
display: flex;
align-items: center;
justify-content: center;
width: 36px;
height: 36px;
background: linear-gradient(135deg, #3498db, #2980b9);
border-radius: 10px;
color: white;
position: relative;
z-index: 1;
box-shadow: 0 4px 10px rgba(52, 152, 219, 0.25);
transition: transform 0.3s ease;
}
.icon::before {
content: '';
position: absolute;
top: -3px;
left: -3px;
right: -3px;
bottom: -3px;
background: linear-gradient(135deg, #3498db, #2980b9);
border-radius: 12px;
z-index: -1;
opacity: 0.4;
filter: blur(5px);
transition: all 0.3s ease;
}
.icon:hover {
transform: translateY(-2px);
}
.icon:hover::before {
opacity: 0.6;
filter: blur(7px);
}
.icon :deep(svg) {
width: 20px;
height: 20px;
}
.title {
font-size: 17px;
font-weight: 600;
color: #2c3e50;
letter-spacing: 0.3px;
position: relative;
}
.title::after {
content: '';
position: absolute;
bottom: -4px;
left: 0;
width: 100%;
height: 2px;
background: linear-gradient(to right, #3498db, transparent);
transform: scaleX(0);
transform-origin: left;
transition: transform 0.3s ease;
}
.title-section:hover .title::after {
transform: scaleX(1);
}
.action-section {
display: flex;
align-items: center;
gap: 16px;
}
.speak-button {
display: flex;
align-items: center;
justify-content: center;
width: 40px;
height: 40px;
border-radius: 8px;
background: #fff;
cursor: pointer;
transition: all 0.3s ease;
color: #3498db;
border: 1px solid rgba(52, 152, 219, 0.3);
box-shadow: 0 2px 8px rgba(52, 152, 219, 0.1);
}
.speak-button:hover {
background: #f0f8ff;
color: #2980b9;
transform: translateY(-2px);
box-shadow: 0 4px 12px rgba(52, 152, 219, 0.2);
}
.speak-button.speaking {
background: linear-gradient(135deg, #3498db, #2980b9);
color: white;
animation: pulse 2s infinite;
box-shadow: 0 4px 12px rgba(52, 152, 219, 0.3);
}
.content-box {
padding: 24px;
min-height: 100px;
position: relative;
transition: all 0.3s ease;
background-color: #fff;
}
.bubble-container {
position: relative;
background-color: #f7fafc;
border-radius: 12px;
padding: 20px;
margin-left: 15px;
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.05);
border-left: 3px solid #3498db;
}
.bubble-decoration {
position: absolute;
left: -10px;
top: 20px;
width: 15px;
height: 15px;
background-color: #f7fafc;
transform: rotate(45deg);
border-left: 3px solid #3498db;
border-bottom: 1px solid transparent;
border-top: 1px solid transparent;
border-right: 1px solid transparent;
}
.loading-box::after {
content: "";
position: absolute;
bottom: 0;
left: 0;
width: 100%;
height: 2px;
background: linear-gradient(to right, transparent, #3498db, transparent);
animation: loadingBar 1.5s infinite;
}
.text {
margin: 0;
line-height: 1.8;
color: #34495e;
font-size: 15px;
letter-spacing: 0.3px;
text-align: justify;
overflow-wrap: break-word;
}
.text.is-typing {
color: #7f8c8d;
}
.cursor {
display: inline-block;
width: 2px;
height: 1em;
background-color: #3498db;
animation: blink 1s infinite;
vertical-align: text-bottom;
margin-left: 2px;
}
.footer {
padding: 12px 20px;
background: #f7fafc;
border-top: 1px solid rgba(235, 235, 235, 0.8);
}
.meta-info {
display: flex;
align-items: center;
justify-content: center;
gap: 8px;
color: #7f8c8d;
font-size: 13px;
}
.meta-info :deep(svg) {
width: 14px;
height: 14px;
color: #3498db;
}
@keyframes pulse {
0% {
transform: scale(1);
box-shadow: 0 4px 12px rgba(52, 152, 219, 0.3);
}
50% {
transform: scale(1.05);
box-shadow: 0 6px 16px rgba(52, 152, 219, 0.4);
}
100% {
transform: scale(1);
box-shadow: 0 4px 12px rgba(52, 152, 219, 0.3);
}
}
@keyframes blink {
0%,
100% {
opacity: 1;
}
50% {
opacity: 0;
}
}
@keyframes loadingBar {
0% {
transform: translateX(-100%);
}
100% {
transform: translateX(100%);
}
}
/* 深色模式适配 */
:root.dark .summary-container {
background: #1a1e22;
border-color: rgba(55, 65, 75, 0.8);
box-shadow: 0 6px 18px rgba(0, 0, 0, 0.25);
}
:root.dark .header {
background: linear-gradient(to right, #1e2a38, #1c2836);
border-color: rgba(45, 55, 65, 0.8);
}
:root.dark .title {
color: #ecf0f1;
}
:root.dark .bubble-container {
background-color: #242a33;
border-left: 3px solid #3498db;
box-shadow: 0 2px 10px rgba(0, 0, 0, 0.15);
}
:root.dark .bubble-decoration {
background-color: #242a33;
border-left: 3px solid #3498db;
}
:root.dark .text {
color: #ecf0f1;
}
:root.dark .text.is-typing {
color: #bdc3c7;
}
:root.dark .speak-button {
background: #2c3e50;
border-color: rgba(52, 152, 219, 0.4);
color: #3498db;
}
:root.dark .speak-button:hover {
background: #34495e;
}
:root.dark .footer {
background: #1e2a38;
border-color: rgba(45, 55, 65, 0.8);
}
:root.dark .meta-info {
color: #95a5a6;
}
/* 响应式设计 */
@media (max-width: 768px) {
.summary-container {
border-radius: 10px;
}
.header {
padding: 14px 16px;
}
.content-box {
padding: 20px 16px;
}
.icon {
width: 32px;
height: 32px;
}
.title {
font-size: 16px;
}
.text {
font-size: 14.5px;
}
.speak-button {
width: 36px;
height: 36px;
}
}
</style>配置
docs\.vitepress\theme\index.js
js
import ArticleGPT from '../../.vitepress/theme/components/ArticleGPT.vue';
enhanceApp({ app }) {
app.component('ArticleGPT', ArticleGPT);
}
docs\.vitepress\config.js
js
markdown: {
config(md) {
md.core.ruler.before('normalize', 'inject-content', (state) => {
// 获取当前 Markdown 文件的 frontmatter 信息
const frontmatter = state.env.frontmatter;
// 检查 frontmatter 是否包含 `show: true`
if (frontmatter && frontmatter.show === true) {
// 动态注入内容
state.src = `<ArticleGPT />\n\n${state.src}`;
}
});
}
}自动化生成摘要
- 我是没有
YAML front matter的,接下来使用AI工具自动生成,自动添加的md中- 存在则覆盖
- 具体见GitHub仓库
使用